User Interface Guide¶
This page explains how to configure and use Assistant Engine’s UI—no developer background required.
First-Time Setup After Download¶
When you first launch Assistant Engine, it comes preloaded with two ready-to-use remote assistants. These allow you to try the system right away, no local setup required:
- Assistant Lite (Recommended For Most Tasks) – Fast, lightweight, ideal for everyday conversations.
- Assistant Pro – Slower, but more capable and reliable. Designed for deeper reasoning and fewer errors.
This means you can immediately test Assistant Engine without installing anything extra.
Running models locally¶
To run models on your own machine (instead of relying only on remote assistants), you’ll need to Install Ollama on the target system. Once Ollama is installed, Assistant Engine will automatically detect your local model server and let you assign downloaded models to any role.
Why install Ollama?
Running models locally keeps your data private, improves speed on capable hardware, and lets you experiment with different model variants (quantized, full-precision, specialized, etc.).
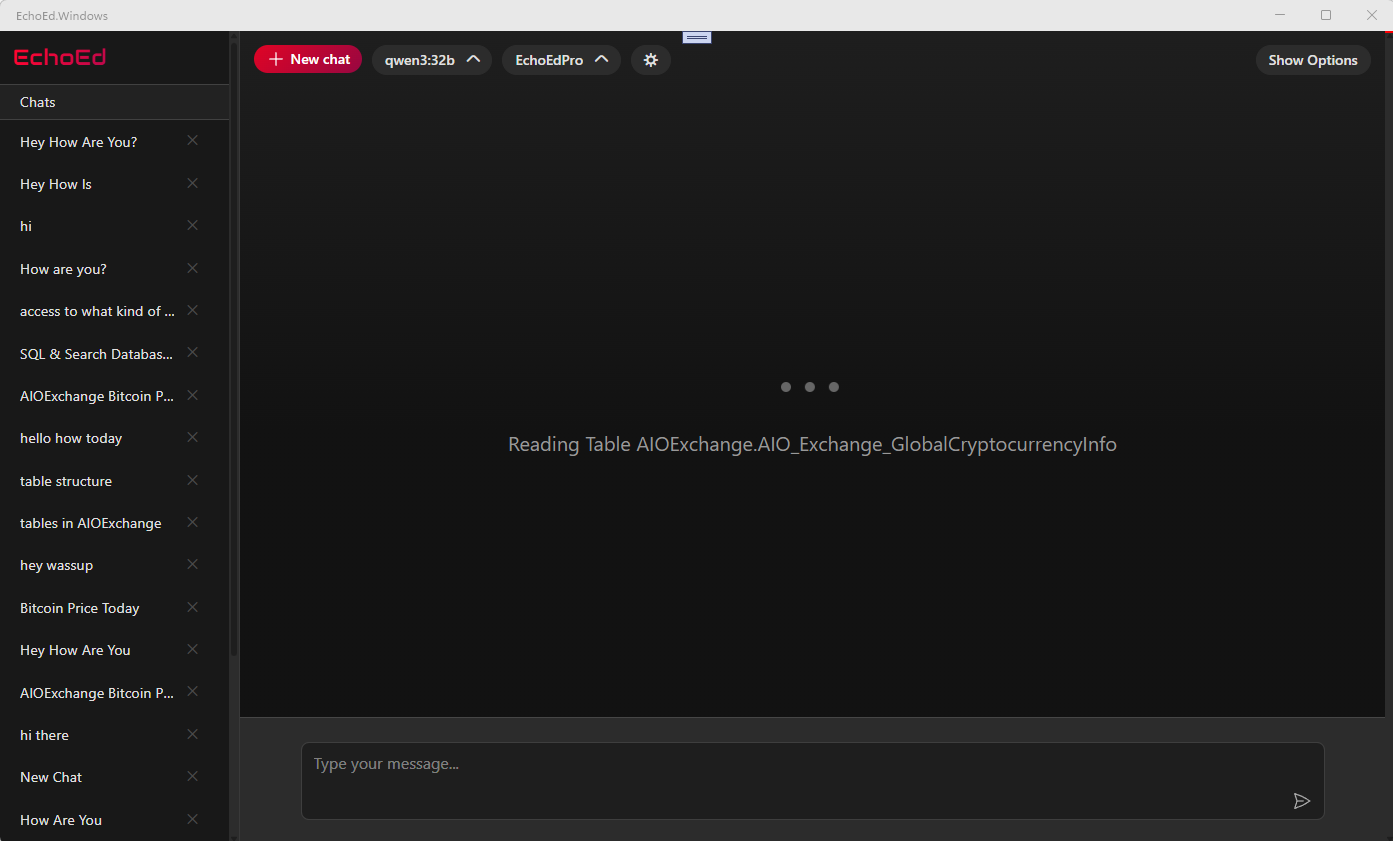
Configure Your Multi-Model Assistant¶
In Assistant Options → Model Configuration (right sidebar), Assistant Engine lets you run several specialized models together. Click each role to adjust its settings, test, and (optionally) save.
Model roles at a glance¶
| Role | What it does | Typical size | When to choose bigger | Notes |
|---|---|---|---|---|
| Assistant | Primary brain: answers your questions and decides which tools to use. | Large | Complex reasoning, longer answers, mixed tasks. | Usually your biggest model. |
| Embedding | Converts documents into vectors for fast semantic search. | Small–Medium | Very large libraries or multilingual content. | A “vectorizer” model; used during ingestion & retrieval. |
| Descriptor | Summarizes your files/tables before embedding (“explain then store”). | Small–Medium | Highly technical data needing richer summaries. | Think “auto-comment your data for better search.” |
| Correction | Offers alternative phrasings/ideas when the Assistant gets stuck. | Small | Rarely needed for simple tasks. | Optional; diversity booster. |
| Text-to-SQL | Turns plain English into SQL for supported databases. | Medium | Complex schemas, tricky joins. | Pairs well with Describe Database (below). |
| Mini Task | Lightweight tasks (e.g., auto-naming chat titles). | Tiny | Almost never. | Background helper only. |
Try before you save
Tune a role, run a quick test, then save if you like the results. You can always revert.
Model settings (what the sliders mean)¶
You’ll see these controls on each role:
- Model – Which local model file/variant to use.
- Temperature – Creativity knob. Lower = precise & consistent. Higher = varied & imaginative.
- Top-p – Keeps only the most likely words whose combined probability is p. Lower = safer, higher = freer wording.
- Top-k – Limits choices to the top k next-word options. Lower = more conservative; higher = more exploratory.
- Max output tokens – Caps the length of the answer. If replies get cut off, raise this.
- Presence penalty – Encourages new topics vs. repeating earlier words/ideas.
- Frequency penalty – Reduces repeated words/phrases within the same reply.
Practical presets
- General chat → Temperature
0.6–0.8, Top-p0.9, Top-k40–100 - Focused / code answers → Temperature
0.2–0.4, Top-p0.8–0.9, Top-k20–50 - Long articles → Increase Max output tokens (and consider a larger Assistant model)
Context (How the agent behaves)¶
In Assistant Options → Context (left sidebar), you define persistent instructions that shape the agent’s tone and priorities.
- System instructions: What the agent should always do (e.g., “be concise,” “use steps”).
- Examples: Short examples of the style you like (Q\&A snippets).
- Tooling preferences: Tell the agent when to search, use SQL, or stick to local files.
- Safety/limits: Define topics to avoid or when to ask for confirmation.
Good context examples
- Prefer accurate, short answers; use bullet points.
- If a database is connected, check it before guessing.
- Cite the source (file or DB table) when answering from my data.
File Access¶
In Assistant Options → RAG / Data Ingestion, click Add Ingestion Path to give your Assistant Model access to files and folders.
Assistant Engine will chunk and vectorize these files, making their content searchable and usable during conversations.
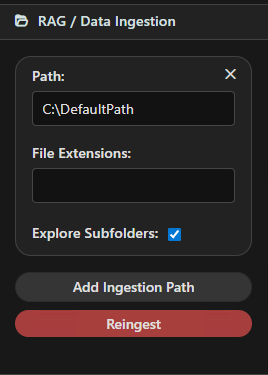
Options explained¶
- Path – The folder or file path to ingest (e.g.,
C:\Projects\Docsor/Users/alex/notes). - File Extensions – Limit ingestion to certain file types (e.g.,
.cs,.md,.pdf).
Useful when you only want specific content. - Explore Subfolders – Toggle whether Assistant Engine should look inside subdirectories automatically.
Disable if you only want the top-level folder.
Best practice
Start small. Add a single folder first, test retrieval, then expand with more sources once you’re confident.
Database Access¶
In Assistant Options → Databases, click Add Database to give your Assistant Model structured access to your data.
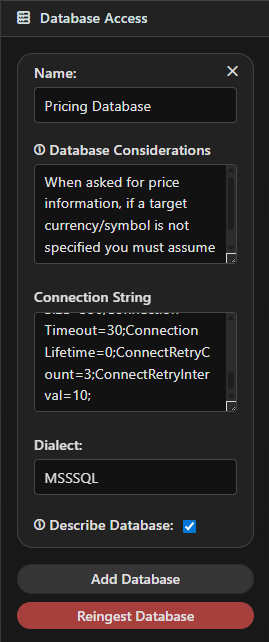
Options explained¶
- Name – A friendly label (e.g., “Sales Warehouse”).
- Connection String – Defines how Assistant Engine connects (server, database, credentials).
Your database admin can supply this. - Dialect – The database type (e.g., SQL Server, PostgreSQL, MySQL).
- Describe Database – If enabled, Assistant Engine uses the Descriptor Model to create summaries of your schema before ingestion.
This improves search and SQL generation accuracy.
Database Considerations¶
- Permissions – Ensure the user account in your connection string has read access.
- Schema Size – Large schemas may take longer to ingest.
- Updates – Re-ingest whenever your schema changes.
- Security – Store credentials securely; avoid sharing them in plaintext.
Best practice
- Add Database to confirm credentials and connectivity.
- Run Ingest to build the vector store.
- Re-ingest if your schema changes.
Adding New Models (via Ollama)¶
In Settings → Models, you can install new models directly from the UI.
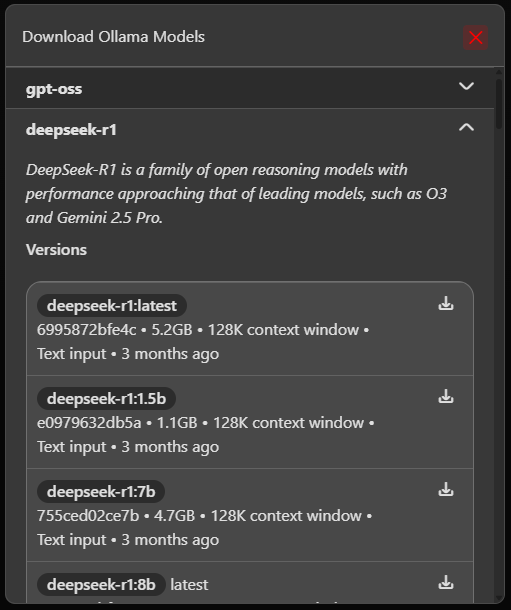
- Open the model dropdown (to the right of Add Chat).
- Select Download new model.
- Pick a model from the list and start the download.
- Wait until the status changes to Ready.
- (Optional) Assign the model to one of your roles in the Chat Options sidebar, then click Save.
Local & Private
All models are pulled from your own Ollama server. Keep in mind: larger models take up more disk space and require more RAM/VRAM.
Global Settings¶
At the very bottom of the left sidebar, click Advanced Settings to open the global configuration panel.
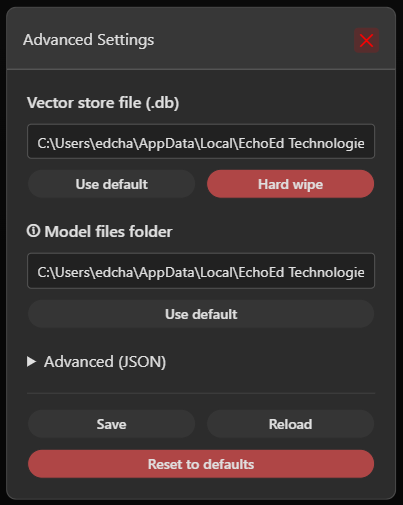
Here you can adjust application-wide options:
- Model files folder – Controls where Assistant Engine saves and loads multi-model configuration files.
- Vector store database – Defines where embeddings are stored.
- Currently this is shared across all configurations.
- Future versions will allow separate vector stores per configuration.
- Import / Export JSON – Back up or restore your global settings in one step.
Restart Required
Changes in Advanced Settings only take effect after restarting Assistant Engine.
Choosing Appropriate Models¶
Pick lighter models if you’re on modest hardware or want faster replies — e.g. a Medium Assistant with Small Embedding/Descriptor models. On stronger machines or for complex work, step up to a Large Assistant, with Medium–Large Text-to-SQL and higher-quality Embedding/Descriptor models. If your workflow leans heavily on search and retrieval, invest in better Descriptor and Embedding quality; if it’s mainly database Q&A, enable Describe Database and choose a stronger Text-to-SQL model.
Quantized vs full-precision
Quantized models run faster with less memory, at some accuracy cost. Start quantized and only move up if you need deeper reasoning.
Having issues ingesting or accessing data?
Open Settings → Data and use Delete Vector Stores, then re-ingest. This fixes most schema/permission changes and stale index issues.